  INDICE SQL SERVER
Introduzione
1.01 - Introduzione a SQL Server
1.02 - Installazione di Sql Server
1.03 - I servizi di SQL Server
1.04 - Management Studio
Struttura
1.05 - I database di SQL Server 2005
1.06 - Creazione Database
1.07 - I tipi di dati
1.08 - Le tabelle
1.09 - Le viste
1.10 - Le stored procedure
1.11 - Creazione di una Stored Procedure
Controlli e legami
1.12 - I vincoli
1.13 - I legami o relazioni
1.14 - I trigger
Query
1.15 - Struttura Select
1.16 - Aggregazione dei dati
1.17 - Interazione con il Framwork .NET
Amministrazione di SQL Server
1.18 - Autenticazione
1.19 - Le regole d'oro
Dal sito HTML.it Guida a Microsoft SQL Server INDICE SQL SERVER
Introduzione
1.01 - Introduzione a SQL Server
1.02 - Installazione di Sql Server
1.03 - I servizi di SQL Server
1.04 - Management Studio
Struttura
1.05 - I database di SQL Server 2005
1.06 - Creazione Database
1.07 - I tipi di dati
1.08 - Le tabelle
1.09 - Le viste
1.10 - Le stored procedure
1.11 - Creazione di una Stored Procedure
Controlli e legami
1.12 - I vincoli
1.13 - I legami o relazioni
1.14 - I trigger
Query
1.15 - Struttura Select
1.16 - Aggregazione dei dati
1.17 - Interazione con il Framwork .NET
Amministrazione di SQL Server
1.18 - Autenticazione
1.19 - Le regole d'oro
Dal sito HTML.it Guida a Microsoft SQL Server
 Ritorna all'indice
1.01 - Introduzione a SQL Server
Questa guida è dedicata all’edizione che più sembra rivoluzionare il modo di fruire SQL Server, come tutte le edizioni Express (gratuite) degli strumenti
di sviluppo visuale di Microsoft: la licenza gratuita favorisce il contatto con questo strumento sempre considerato molto “professionale”, anche chi fino
a ieri preferiva lavorare con i file mdb di Access per piccole applicazioni, o con la precedente versione gratuita MSDE, può effettuare il passaggio ad uno
strumento estremamente più potente.
La guida ci accompagnerà passo dopo passo nell’installazione del database, nella successiva configurazione, per poi passare ad analizzare i vari oggetti
presenti in Sql Server, nonchè il nuovo strumento IDE fornito da Microsoft, Sql Management Studio Express che ha sostituito i famosi Query Analyzer e in
parte l’Enterprise Manager.
Ritorna all'indice
1.01 - Introduzione a SQL Server
Questa guida è dedicata all’edizione che più sembra rivoluzionare il modo di fruire SQL Server, come tutte le edizioni Express (gratuite) degli strumenti
di sviluppo visuale di Microsoft: la licenza gratuita favorisce il contatto con questo strumento sempre considerato molto “professionale”, anche chi fino
a ieri preferiva lavorare con i file mdb di Access per piccole applicazioni, o con la precedente versione gratuita MSDE, può effettuare il passaggio ad uno
strumento estremamente più potente.
La guida ci accompagnerà passo dopo passo nell’installazione del database, nella successiva configurazione, per poi passare ad analizzare i vari oggetti
presenti in Sql Server, nonchè il nuovo strumento IDE fornito da Microsoft, Sql Management Studio Express che ha sostituito i famosi Query Analyzer e in
parte l’Enterprise Manager.
Ritorna all'indice
1.02 - Installazione di Sql Server
Una volta avviato il file di setup dobbiamo accettare la licenza e successivamente verrà effettuata una scansione del sistema per reperire le informazioni
di compatibilità. Attenzione, non è possibile installare un’instanza della versione 2005 in una macchina dove già è installata una versione 2000.
 Figura 1. Controllo del sistema
In base alle informazioni reperite in questa fase, sappiamo se il nostro sistema è in grado di supportare SQL Server 2005.
Le principali verifiche vengono effettuate su MDAC, WMI, IIS e il Framework .NET.
Il passo successivo sarà quello di selezionare le opzioni da installare. Per seguire correttamente tutta la guida è consigliabile installare completamente
sia la “parte Server”, sia la “parte Client” per avere sulla macchina un sistema ottimale, inoltre è possibile anche installare la funzione accessoria di
reportistica fornita con il “Reporting Services”.
Figura 1. Controllo del sistema
In base alle informazioni reperite in questa fase, sappiamo se il nostro sistema è in grado di supportare SQL Server 2005.
Le principali verifiche vengono effettuate su MDAC, WMI, IIS e il Framework .NET.
Il passo successivo sarà quello di selezionare le opzioni da installare. Per seguire correttamente tutta la guida è consigliabile installare completamente
sia la “parte Server”, sia la “parte Client” per avere sulla macchina un sistema ottimale, inoltre è possibile anche installare la funzione accessoria di
reportistica fornita con il “Reporting Services”.
 Figura 2. Selezione delle opzioni di installazione
Al termine dell’installazione, nel caso in cui abbiamo scelto di installare tutto, otteniamo un motore di database in versione Express completo di servizi
TCP e PIPES, uno strumento per interagire con il db e un completo servizio di reportistica. Se invece abbiamo scaricato solamente il motore di database,
installaremo a parte sia il “Management Studio Express”, sia il Reporting Services.
Figura 2. Selezione delle opzioni di installazione
Al termine dell’installazione, nel caso in cui abbiamo scelto di installare tutto, otteniamo un motore di database in versione Express completo di servizi
TCP e PIPES, uno strumento per interagire con il db e un completo servizio di reportistica. Se invece abbiamo scaricato solamente il motore di database,
installaremo a parte sia il “Management Studio Express”, sia il Reporting Services.
Ritorna all'indice
1.03 - I servizi di SQL Server
Configurazione
Il primo passaggio da effettuare, una volta terminata la fase di installazione, è quello di avviare i servizi presenti nella nostra macchina e verificare
lo stato del motore di database.
Questo perché, al contrario delle versioni precedenti, adesso gli strumenti Microsoft seguono la logica UNIX, ovvero nessuna installazione accessoria se non
necessaria. In questo modo sono stati ridotti gli attacchi esterni causati proprio da funzioni installate di default.
Per avviare i servizi apriamo dal menù programmi, del menù start, lo strumento Configurazione.
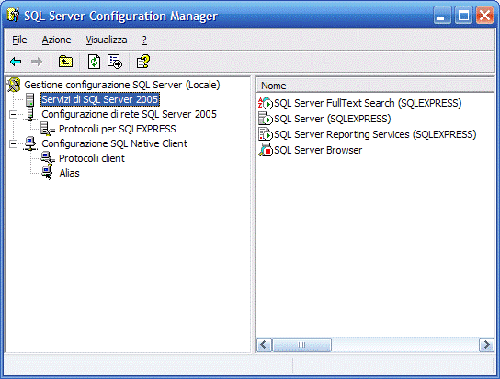 Figura 1. Configurazione di Sql Server
Il nodo principale indica i servizi istallati e quali tra questi sono attivi.
Il servizio FullText offre la funzionalità per creare query full-text, su dati di tipo carattere, nelle tabelle di SQL Server.
Le query full-text possono includere parole e frasi o forme diverse di una parola o frase.
Gli altri servizi sono: il vero e proprio motore di database e il servizio di reportistica opzionale.
Nei nodi possiamo configurare il tipo di comunicazione e protocolli.
Se la nostra necessità sarà quella di rendere visibile il database in rete, dovremo inizializzare un servizio come TCP o PIPES.
infine possiamo aggiungere un nome al nostro database creando un Alias.
La superficie di attacco
Il nuovo concetto di sicurezza introdotto da Microsoft negli ultimi anni, fa si che una volta installato un prodotto, i servizi e le configurazioni che
potrebbero essere utilizzate in maniera sbagliata e pericolosa, vengono di base disabilitati. Questo vuol dire che dopo l’installazione, il nostro database
non sarà comunque visibile ed accessibile dall’esterno, proprio per una politica che sostiene la sicurezza. Per poter rendere completamente visibile e agibile
dall’esterno il nostro database, dobbiamo utilizzare uno strumento che si chiama Gestione superficie di attacco, che possiamo trovare sempre nella cartella di
Sql 2005.
Figura 1. Configurazione di Sql Server
Il nodo principale indica i servizi istallati e quali tra questi sono attivi.
Il servizio FullText offre la funzionalità per creare query full-text, su dati di tipo carattere, nelle tabelle di SQL Server.
Le query full-text possono includere parole e frasi o forme diverse di una parola o frase.
Gli altri servizi sono: il vero e proprio motore di database e il servizio di reportistica opzionale.
Nei nodi possiamo configurare il tipo di comunicazione e protocolli.
Se la nostra necessità sarà quella di rendere visibile il database in rete, dovremo inizializzare un servizio come TCP o PIPES.
infine possiamo aggiungere un nome al nostro database creando un Alias.
La superficie di attacco
Il nuovo concetto di sicurezza introdotto da Microsoft negli ultimi anni, fa si che una volta installato un prodotto, i servizi e le configurazioni che
potrebbero essere utilizzate in maniera sbagliata e pericolosa, vengono di base disabilitati. Questo vuol dire che dopo l’installazione, il nostro database
non sarà comunque visibile ed accessibile dall’esterno, proprio per una politica che sostiene la sicurezza. Per poter rendere completamente visibile e agibile
dall’esterno il nostro database, dobbiamo utilizzare uno strumento che si chiama Gestione superficie di attacco, che possiamo trovare sempre nella cartella di
Sql 2005.
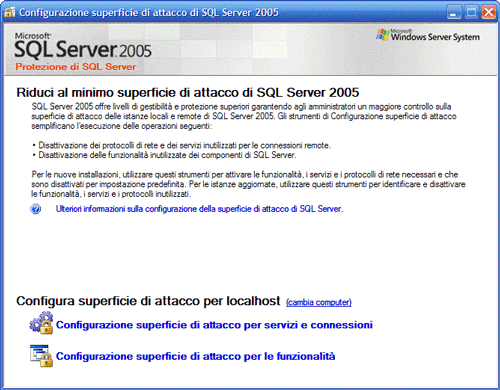 Figura 2. Avvio gestione superficie
Tramite questo strumento possiamo gestire la visibilità del database nella rete.
Se avete seguito la parte di configurazione, sfogliando i vari servizi presenti nella parte di gestione, noterete che abbiamo abilitato un po’ tutto e quindi
il nostro database sarà visibile dagli altri client semplicemente chiamandolo [nome_macchina][nome_database].
Possiamo dire che la sezione dei servizi è la stessa che possiamo trovare nell’elenco dei servizi che Sql espone, qui viene solamente presentata attraverso uno
strumento.
La seconda schermata, legata alle funzionalità serve per avviare una configurazione avanzata del database.
Ad esempio, Sql Server 2005 supporta una piena integrazione con il .NET Framework, tramite SQLCLR.
Questo ambiente integrato in CLR (Common Language Runtime) supporta oggetti di database procedurali, incluse funzioni, stored e trigger, scritti nei linguaggi
.NET, ad esempio C# e VB.NET.
I linguaggi che si basano sul framework .NET supportano funzioni e logica non disponibili nel linguaggio Transact-SQL, come ad esempio le RegularExpression,
il che consente di incorporare una logica più complessa negli oggetti di database.
È inoltre possibile scrivere tipi e funzioni di aggregazione definiti dall’utente in linguaggi .NET per creare tipi di dati più complessi di quelli disponibili
nelle versioni precedenti di SQL Server.
Figura 2. Avvio gestione superficie
Tramite questo strumento possiamo gestire la visibilità del database nella rete.
Se avete seguito la parte di configurazione, sfogliando i vari servizi presenti nella parte di gestione, noterete che abbiamo abilitato un po’ tutto e quindi
il nostro database sarà visibile dagli altri client semplicemente chiamandolo [nome_macchina][nome_database].
Possiamo dire che la sezione dei servizi è la stessa che possiamo trovare nell’elenco dei servizi che Sql espone, qui viene solamente presentata attraverso uno
strumento.
La seconda schermata, legata alle funzionalità serve per avviare una configurazione avanzata del database.
Ad esempio, Sql Server 2005 supporta una piena integrazione con il .NET Framework, tramite SQLCLR.
Questo ambiente integrato in CLR (Common Language Runtime) supporta oggetti di database procedurali, incluse funzioni, stored e trigger, scritti nei linguaggi
.NET, ad esempio C# e VB.NET.
I linguaggi che si basano sul framework .NET supportano funzioni e logica non disponibili nel linguaggio Transact-SQL, come ad esempio le RegularExpression,
il che consente di incorporare una logica più complessa negli oggetti di database.
È inoltre possibile scrivere tipi e funzioni di aggregazione definiti dall’utente in linguaggi .NET per creare tipi di dati più complessi di quelli disponibili
nelle versioni precedenti di SQL Server.
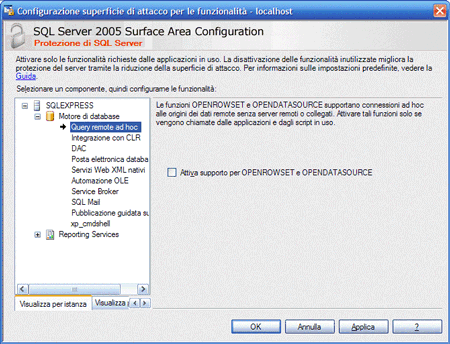 Figura 3. Funzionalità di Sql Server
Ricapitolando in questa fase stiamo attivando l’istanza di SQL presente sulla macchina. Dobbiamo avviare i seguenti servizi: il motore di database, l’accesso
remoto tramite TCP o PIPES, la ricerca full-text, l’integrazione con il CLR e la xp_cmdshell che ci consente l’utilizzo di SQLCMD da schermate tipo DOS.
A questo punto il nostro motore di Database è pronto per poter essere manipolato.
Figura 3. Funzionalità di Sql Server
Ricapitolando in questa fase stiamo attivando l’istanza di SQL presente sulla macchina. Dobbiamo avviare i seguenti servizi: il motore di database, l’accesso
remoto tramite TCP o PIPES, la ricerca full-text, l’integrazione con il CLR e la xp_cmdshell che ci consente l’utilizzo di SQLCMD da schermate tipo DOS.
A questo punto il nostro motore di Database è pronto per poter essere manipolato.
Ritorna all'indice
1.04 - Management Studio
In questa nuova versione di Sql Server, viene fornito uno strumento completo per poter operare completamente in maniera visuale con il motore di database.
Questo non vuol dire che non possiamo continuare ad operare tramite sintassi T-SQL.
Con il Management Studio Express, che è una versione con meno funzioni di quella completa, siamo in grado di gestire tutti gli oggetti dei nostri database,
di operare con T-SQL e di salvare e gestire script T-SQL, ma non solo.
IDE di Management Studio
Una volta avviato il Management Studio, viene subito richiesa una credenziale di accesso per poter accedere al sistema.
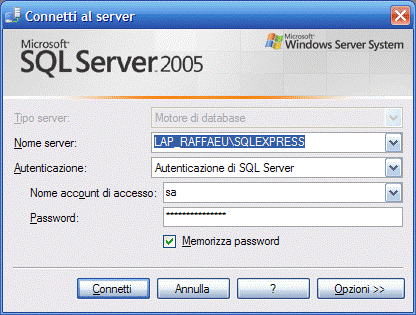 Figura 1. Schermata di Login
Possiamo scegliere se accedere tramite il nostro attuale utente di windows, oppure tramite un utene presente in Sql Server, che potrebbe essere, ad esempio,
l’utente SA.
Nella sezione sinistra dell’IDE, ci viene presentato un pannello contenente tutti i database presenti nella nostra istanza Sql, e per ogni database è presente
un corposo menù ad albero che elenca gli oggetti.
Avremo quindi le tabelle, le viste, le stored procedure. In ogni tabella avremo elencati i campi, le chiavi, gli indici e così via per tutti gli oggetti.
Figura 1. Schermata di Login
Possiamo scegliere se accedere tramite il nostro attuale utente di windows, oppure tramite un utene presente in Sql Server, che potrebbe essere, ad esempio,
l’utente SA.
Nella sezione sinistra dell’IDE, ci viene presentato un pannello contenente tutti i database presenti nella nostra istanza Sql, e per ogni database è presente
un corposo menù ad albero che elenca gli oggetti.
Avremo quindi le tabelle, le viste, le stored procedure. In ogni tabella avremo elencati i campi, le chiavi, gli indici e così via per tutti gli oggetti.
 Figura 2. Sezione esplora oggetti
In questo caso il pannello centrale ci torna utile per evidenziare il dettaglio dell’oggetto selezionato nella finestra esplora.
Questo pannello viene anche utilizzato per la scrittura di comandi SQL. Unica pecca di questa sezione è la completa mancanza di uno strumento di IntelliSense,
che però può essere integrato con uno strumento gratuito della RedGate che si chiama SQL Prompt.
Infine, è presente una sezione al di sotto dell’elenco dei database, utile per la gestione e creazione di utenti e per l’assegnazione di permessi, che comprende
tutte le informazioni necessarie a configurare la sicurezza in SQL server.
I modelli predefiniti
Nel Management Studio di SQL 2005 possiamo trovare, nel pannello di destra, numerosi Modelli di database già pronti all’uso.
Per attivare questa finestra basta andare nel menù Visualizza --> Modelli.
In questo pannello non troviamo solamente modelli di database o tabelle, ma tutta una serie di utilità per poter operare sul database e su i suoi oggetti.
Possiamo ad esempio aprire uno scirpt SQL per la creazione di un backup, oppure per creare dei Ruoli nel nostro database.
È inoltre possibile creare dei propri modelli di codice SQL, ad esempio, per poter gestire la produttività.
Per creare un proprio modello, bisogna inserire una nuova cartella nell’albero modelli.
A questo punto avrete a disposizione l’editor T-SQL nel quale potrete inserire tutto il codice che serve al modello.
Sicuramente questa parte di configurazione sarà ripetitiva, ma una volta creata una propria libreria di modelli di codice, la vostra produttività aumenterà
vertiginosamente.
Piano di esecuzione
Uno strumento molto importante presente nel Management Studio è il Piano di esecuzione.
Tramite questo strumento possiamo valutare le prestazioni della nostra richiesta al server e capire quindi se la query che abbiamo impostato è performante o meno.
Ad esempio possiamo capire se in una determinata vista gli indici che stiamo usando sono corretti o no.
Una volta impostata la query, premendo il pulsante Piano di esecuzione, quest’ultima viene eseguita mostrando le statistiche di esecuzione.
Figura 2. Sezione esplora oggetti
In questo caso il pannello centrale ci torna utile per evidenziare il dettaglio dell’oggetto selezionato nella finestra esplora.
Questo pannello viene anche utilizzato per la scrittura di comandi SQL. Unica pecca di questa sezione è la completa mancanza di uno strumento di IntelliSense,
che però può essere integrato con uno strumento gratuito della RedGate che si chiama SQL Prompt.
Infine, è presente una sezione al di sotto dell’elenco dei database, utile per la gestione e creazione di utenti e per l’assegnazione di permessi, che comprende
tutte le informazioni necessarie a configurare la sicurezza in SQL server.
I modelli predefiniti
Nel Management Studio di SQL 2005 possiamo trovare, nel pannello di destra, numerosi Modelli di database già pronti all’uso.
Per attivare questa finestra basta andare nel menù Visualizza --> Modelli.
In questo pannello non troviamo solamente modelli di database o tabelle, ma tutta una serie di utilità per poter operare sul database e su i suoi oggetti.
Possiamo ad esempio aprire uno scirpt SQL per la creazione di un backup, oppure per creare dei Ruoli nel nostro database.
È inoltre possibile creare dei propri modelli di codice SQL, ad esempio, per poter gestire la produttività.
Per creare un proprio modello, bisogna inserire una nuova cartella nell’albero modelli.
A questo punto avrete a disposizione l’editor T-SQL nel quale potrete inserire tutto il codice che serve al modello.
Sicuramente questa parte di configurazione sarà ripetitiva, ma una volta creata una propria libreria di modelli di codice, la vostra produttività aumenterà
vertiginosamente.
Piano di esecuzione
Uno strumento molto importante presente nel Management Studio è il Piano di esecuzione.
Tramite questo strumento possiamo valutare le prestazioni della nostra richiesta al server e capire quindi se la query che abbiamo impostato è performante o meno.
Ad esempio possiamo capire se in una determinata vista gli indici che stiamo usando sono corretti o no.
Una volta impostata la query, premendo il pulsante Piano di esecuzione, quest’ultima viene eseguita mostrando le statistiche di esecuzione.
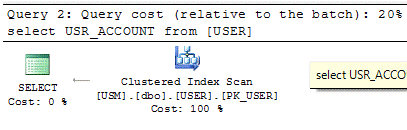 Figura 3. Piano di esecuzione
Figura 3. Piano di esecuzione
Ritorna all'indice
1.05 - I database di SQL Server 2005
Un database di SQL Server 2005 è costituito da un insieme di oggetti che contengono dati, ad esempio viste e tabelle, e da altri oggetti che legano tra loro questi
dati, quali indici, stored procedure, funzioni definite dall’utente e trigger.
Alle tabelle che contengono i dati sono associati numerosi tipi di controlli, ad esempio vincoli, trigger, valori predefiniti e tipi di dati utente personalizzati,
che garantiscono la validità dei dati.
È possibile aggiungere vincoli di integrità referenziale dichiarativa (DRI, Declarative Referential Integrity) alle tabelle per garantire che i dati correlati delle
diverse tabelle rimangano consistenti.
Nelle tabelle è possibile includere indici, con caratteristiche molto simili a quelli dei libri, che consentono di trovare rapidamente le righe.
Un database può, inoltre, contenere procedure che utilizzano codice di programmazione Transact-SQL o .NET Framework per eseguire operazioni con i dati del database.
Tali operazioni includono la creazione di viste che offrono accesso personalizzato ai dati della tabella o di una funzione definita dall’utente per l’esecuzione di
un calcolo complesso in un subset di righe.
Un’istanza di SQL Server può supportare più database. Ogni database consente di archiviare dati correlati o non correlati di altri database.
In un’istanza di SQL Server possono, ad esempio, essere presenti un database in cui sono archiviati i dati sul personale e un altro in cui sono archiviati i dati
relativi ai prodotti. In alternativa, è possibile archiviare in un database i dati aggiornati sugli ordini dei clienti e in un altro database correlato la cronologia
degli ordini da utilizzare per la creazione di report annuali.
I Database di sistema
SQL Server 2005 utilizza diversi Database, installati e configurati nel motore già dal primo avvio.
Questi Database servono al sistema, per poter funzionare correttamente, e al programmatore, per poter velocizzare la produzione.
Master
Nel database master vengono registrate tutte le informazioni relative a un sistema SQL Server. Questo è il più importante dei database di sistema, il backup deve
essere fatto regolarmente, perché senza il master, SQL Server può cessare di esistere.
Model
Il Database model contiene un modello di tutti i database presenti nel sistema. Le modifiche a questo database saranno presenti in tutti i database creati ex-novo.
MSDB
Il Database MSDB viene utilizzato da SQL Server Agent per la pianificazione degli avvisi e dei processi nonché per la registrazione degli operatori.
Nel database MSDB sono inoltre presenti tabelle di cronologia, come per esempio le tabelle di cronologia di backup e ripristino.
TempDB
Il Database tempdb non è altro che un’area di lavoro per il mantenimento dei set di risultati temporanei o intermedi.
Questo database viene ricreato ogni volta che viene avviata un’istanza di SQL Server.
Quando l’istanza del server viene chiusa, i dati inclusi in tempdb vengono eliminati in modo definitivo.
Ritorna all'indice
1.06 - Creazione Database
In questa guida andremo ad utilizzare un Database di esempio che chiameremo MyDatabase.
La procedura per creare un Database in SQL 2005 può essere eseguita in due modi: primo tramite script T-SQL, secondo tramite il Management Studio.
Creazione con Management Studio
Tramite Management Studio, per creare un nuovo Database, dobbiamo posizionarci sopra la cartella Database, premere il tasto destro del mouse e scegliere
nuovo database.
 Figura 1. Creazione Database
A questo punto ci viene proposta una finestra composta da diverse proprietà.
Figura 1. Creazione Database
A questo punto ci viene proposta una finestra composta da diverse proprietà.
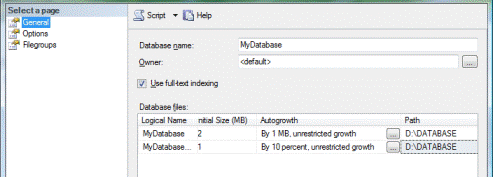 Figura 2. Creazione Database
Per prima cosa dobbiamo assegnare un nome al nostro Database e questa operazione può essere effettuata tramite la casella di testo nome database.
Successivamente, dobbiamo assegnare i permessi al nostro database tramite la proprietà owner. In questo caso lasciamo la dicitura default, vedremo
in seguito come creare un utente in SQL 2005 e assegnarlo ad un determinato Database. Infine dobbiamo posizionare i file del Database.
Il primo con estensione .mdf non è altro che il contenuto del nostro Database, comprensivo di oggetti e dati. Il secondo, .ldf è il file di LOG del Database
che se non controllato correttamente può assumere dimensioni gigantesche.
Creazione con T-SQL
Nel caso in cui volessimo creare il Database tramite sintassi T-SQL il passaggio risulta più semplice. Dobbiamo sempre impostare il nome, i permessi e la
destinazione, ma tutto in un unico script.
USE [master]
GO
CREATE DATABASE [MyDatabase] ON PRIMARY
(NAME = N’MyDatabasÈ, FILENAME = N’D:DATABASEMyDatabase.mdf’, SIZE = 2048KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB)
LOG ON
(NAME = N’MyDatabase_log’, FILENAME = N’D:DATABASEMyDatabase_log.ldf’ , SIZE = 1024KB , MAXSIZE = 1GB , FILEGROWTH = 10%)
COLLATE SQL_Latin1_General_CP1_CI_AS
GO
EXEC dbo.sp_dbcmptlevel @dbname=N’MyDatabasÈ, @new_cmptlevel=90
GO
IF (1 = FULLTEXTSERVICEPROPERTY(‘IsFullTextInstalled’))
begin
EXEC [MyDatabase].[dbo].[sp_fulltext_database] @action = ‘enablÈ
end
GO
Listato 1. Creazione Database
Abbiamo creato il file di database e lo abbiamo registrato nel master. Abbiamo successivamente attivato il file di LOG dandogli però una dimensione idonea
al disco della macchina. Infine abbiamo attivato il servizio di FULLTEXT che andremo ad analizzare di seguito nella guida.
Possiamo impostare tutte le proprietà del database sempre tramite T-SQL. Se esiste già il database lo script dovrà iniziare con la dichiarazione ALTER DATABASE,
seguita dalle proprietà che volgiamo modificare.
USE [master]
GO
ALTER DATABASE [MyDatabase] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [MyDatabase] SET ANSI_NULLS OFF
GO
Listato 2. Modifica Proprietà
Figura 2. Creazione Database
Per prima cosa dobbiamo assegnare un nome al nostro Database e questa operazione può essere effettuata tramite la casella di testo nome database.
Successivamente, dobbiamo assegnare i permessi al nostro database tramite la proprietà owner. In questo caso lasciamo la dicitura default, vedremo
in seguito come creare un utente in SQL 2005 e assegnarlo ad un determinato Database. Infine dobbiamo posizionare i file del Database.
Il primo con estensione .mdf non è altro che il contenuto del nostro Database, comprensivo di oggetti e dati. Il secondo, .ldf è il file di LOG del Database
che se non controllato correttamente può assumere dimensioni gigantesche.
Creazione con T-SQL
Nel caso in cui volessimo creare il Database tramite sintassi T-SQL il passaggio risulta più semplice. Dobbiamo sempre impostare il nome, i permessi e la
destinazione, ma tutto in un unico script.
USE [master]
GO
CREATE DATABASE [MyDatabase] ON PRIMARY
(NAME = N’MyDatabasÈ, FILENAME = N’D:DATABASEMyDatabase.mdf’, SIZE = 2048KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB)
LOG ON
(NAME = N’MyDatabase_log’, FILENAME = N’D:DATABASEMyDatabase_log.ldf’ , SIZE = 1024KB , MAXSIZE = 1GB , FILEGROWTH = 10%)
COLLATE SQL_Latin1_General_CP1_CI_AS
GO
EXEC dbo.sp_dbcmptlevel @dbname=N’MyDatabasÈ, @new_cmptlevel=90
GO
IF (1 = FULLTEXTSERVICEPROPERTY(‘IsFullTextInstalled’))
begin
EXEC [MyDatabase].[dbo].[sp_fulltext_database] @action = ‘enablÈ
end
GO
Listato 1. Creazione Database
Abbiamo creato il file di database e lo abbiamo registrato nel master. Abbiamo successivamente attivato il file di LOG dandogli però una dimensione idonea
al disco della macchina. Infine abbiamo attivato il servizio di FULLTEXT che andremo ad analizzare di seguito nella guida.
Possiamo impostare tutte le proprietà del database sempre tramite T-SQL. Se esiste già il database lo script dovrà iniziare con la dichiarazione ALTER DATABASE,
seguita dalle proprietà che volgiamo modificare.
USE [master]
GO
ALTER DATABASE [MyDatabase] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [MyDatabase] SET ANSI_NULLS OFF
GO
Listato 2. Modifica Proprietà
Ritorna all'indice
1.07 - I tipi di dati
In SQL Server 2005 a ogni colonna, variabile locale, espressione e parametro è associato un attributo che specifica i tipi di dati che l’oggetto può contenere,
ovvero numeri interi, caratteri, valute, date e ore, stringhe binarie e così via.
Conoscere i tipi di dati e saperli usare correttamente significa aumentare drasticamente le performance del Database nonché la forte diminuzione delle sue dimensioni.
All’interno di SQL Server 2005 i tipi di dati sono suddivisi nelle seguenti categorie:
- Dati numerici esatti
- Stringhe di testo Unicode
- Numerici approssimati
- Stringhe binarie
- Data e ora
- Altri tipi di dati
- Stringhe di caratteri
Dati numerici esatti
Tipi di dati numerici esatti che utilizzano dati integer:
- bigint: dati di dimensioni a 8 byte. Da -2^63 a 2^63-1
- int: dati di dimensioni a 4 byte. Da -2^31 a 2^31-1
- smallint: dati di dimensioni a 2 byte. Da -2^15 a 2^15-1
- tinyint: dati di dimensioni a 1 byte. Da 0 a 255
- bit: può assumere il valore 0 o 1. Il valore true viene convertito in 1 e false in 0
- decimal: numeri con precisione e scala fisse. Se viene utilizzata la precisione massima, i valori validi sono compresi nell’intervallo da – 10^38 +1 a 10^38 – 1
- numeric: funzionalmente è come decimal
- money: dati di dimensioni a 8 byte.
- smallmoney: dati di dimensioni a 4 byte.
Numerici approssimati
Tipi di dati numerici approssimati da utilizzare con dati numerici a virgola mobile.
- float: da – 1,79E+308 a -2,23E-308, 0 e da 2,23E-308 a 1,79E+308
- real: da – 3,40E + 38 a -1,18E – 38, 0 e da 1,18E – 38 a 3,40E + 38
Data e ora
Tipi di dati che vengono utilizzati per rappresentare la data e l’ora del giorno
- datetime: 1 gennaio 1753 – 31 dicembre 9999
- smalldatetime: 1 gennaio 1900 – 6 giugno 2079
Stringhe e caratteri
Tipo di dati character a lunghezza fissa o variabile:
- char: dati di tipo carattere a lunghezza fissa non Unicode con una lunghezza di n byte. n deve essere un valore compreso tra 1 e 8.000.
Le dimensioni di archiviazione sono di n byte. Il sinonimo utilizzato in SQL 2003 per char è character.
- varchar: dati di tipo carattere a lunghezza variabile non Unicode. Le dimensioni di archiviazione sono pari all’effettiva lunghezza dei dati immessi + 2 byte.
La lunghezza dei dati immessi può essere uguale a 0 caratteri. I sinonimi utilizzati in SQL 2003 per varchar sono char varying o character varying.
- text: dati non Unicode a lunghezza variabile nella tabella codici del server con lunghezza massima di 2^31-1 caratteri.
Quando la tabella codici del server utilizza caratteri DBCS, lo spazio di archiviazione è sempre pari a 2.147.483.647 byte. In base alla stringa di caratteri,
le dimensioni dello spazio di archiviazione possono essere minori di 2.147.483.647 byte
Stringhe di caratteri UNICODE
Tipi di dati carattere che rappresentano dati UNICODE a lunghezza fissa (nchar) o variabile (nvarchar) e utilizzano il set di caratteri UNICODE UCS-2.
- nchar:: dati Unicode di tipo carattere a lunghezza fissa contenenti n caratteri, dove n deve essere un valore compreso tra 1 e 4.000.
Le dimensioni di archiviazione sono pari al doppio di n byte. I sinonimi di SQL-2003 per il tipo di dati nchar sono national char e national character
- nvarchar:: dati Unicode di tipo carattere a lunghezza variabile. Le dimensioni di archiviazione, espresse in byte, sono pari al doppio del numero di
caratteri immessi + 2 byte. La lunghezza dei dati immessi può essere uguale a 0 caratteri. I sinonimi di SQL-2003 per il tipo di dati nvarchar sono national
char varying e national character varying
- ntext:: dati Unicode a lunghezza variabile con lunghezza massima di 2^30 – 1 caratteri. Le dimensioni dello spazio di archiviazione, espresse in byte,
sono pari al doppio del numero di caratteri immessi. Il sinonimo di SQL-2003 per ntext è national text
Stringhe binarie
Tipi di dati binary a lunghezza fissa o variabile.
- binary: dati binari a lunghezza fissa con lunghezza di n byte, dove n rappresenta un valore compreso tra 1 e 8.000.
Le dimensioni dello spazio di archiviazione corrispondono a n byte.
- varbinary: dati binari a lunghezza variabile
- image: dati binari a lunghezza variabile da 0 a 2^31-1 byte
Altri tipi di dati
Tutti gli altri tipi di dati che non possono essere catalogati nelle categorie precedenti:
- cursor: tipo di dati per variabili o parametri di OUTPUT di stored procedure che contengono un riferimento a un cursore
- sql variant: tipo di dati per l’archiviazione di valori per vari tipi di dati supportati da SQL Server 2005
- table: tipo di dati speciale utilizzabile per archiviare un set di risultati per l’elaborazione successiva
- timestamp: tipo di dati che espone i numeri binari univoci generati automaticamente all’interno di un database
- uniqueidentifier: è possibile inizializzare una colonna o variabile locale di tipo uniqueidentifier su un valore specifico
- xml: tipo di dati in cui vengono archiviati i dati XML. È possibile archiviare istanze xml in una colonna oppure una variabile di tipo xml.
Ritorna all'indice
1.08 - Le tabelle
Le tabelle sono oggetti di database che contengono tutti i dati disponibili in un database. Nelle tabelle, i dati sono organizzati in righe e colonne in un
formato simile a quello di un foglio di calcolo. Ogni riga rappresenta un record univoco e ogni colonna rappresenta un campo all’interno del record.
Ad esempio, una tabella che include i dati dei dipendenti di un’azienda può contenere una riga per ogni dipendente e colonne che rappresentano i dettagli dei
dipendenti quali l’ID, il nome, l’indirizzo, la posizione, ecc.
Dopo avere progettato un database, è possibile creare le tabelle in cui verranno archiviati i dati del database.
È possibile definire fino a 1.024 colonne per tabella. I nomi di tabelle e colonne devono essere conformi alle regole per gli identificatori e devono essere
univoci all’interno di ogni tabella, ma è possibile utilizzare lo stesso nome di colonna in tabelle diverse dello stesso database.
Creazione delle Tabelle
Come per la creazione di un database, anche per la creazione delle tabelle possiamo utilizzare la classica sintassi T-SQL oppure lo strumento Management Studio.
Partiamo con la creazione di una semplice tabella di esempio, che costituirà il contenitore delle informazioni anagrafiche dei clienti.
La tabella si chiamerà TBL_ANAGRAFICA ed ogni campo avrà come suffisso la dicitura ANA_.
Creazione tramite Management Studio
Tramite il Management Studio basta posizionare il mouse sopra la cartella Tabelle del nostro Database e premere il tasto destro -> Nuova tabella.
 Figura 1. Crea Tabella
A questo punto dovrebbe comparire una griglia simile a un foglio di calcolo, nella quale possiamo inserire i nostri campi.
Figura 1. Crea Tabella
A questo punto dovrebbe comparire una griglia simile a un foglio di calcolo, nella quale possiamo inserire i nostri campi.
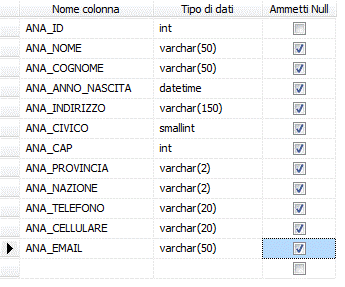 Figura 2. Risultato finale
Per ogni campo creato è possibile inserire molte informazioni. Queste informazioni le troviamo nel pannello sotto la griglia.
Come si può notare le informazioni visualizzate cambiano in base al tipo di dato che stiamo assegnando al campo stesso.
USE [MyDatabase]
GO
CREATE TABLE [dbo].[ANAGRAFICA](
[ANA_ID] [int] IDENTITY(1,1) NOT NULL,
[ANA_NOME] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_COGNOME] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_ANNO_NASCITA] [datetime] NULL,
[ANA_INDIRIZZO] [varchar](150) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_CIVICO] [smallint] NULL,
[ANA_CAP] [int] NULL,
[ANA_PROVINCIA] [varchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_NAZIONE] [varchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_TELEFONO] [varchar](20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_CELLULARE] [varchar](20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_EMAIL] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT [PK_ANAGRAFICA] PRIMARY KEY CLUSTERED
(
[ANA_ID] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
Listato 1. T-SQL per creazione tabella Anagrafica
Il campo ANA_ID è di tipo contatore, quindi utilizziamo l’attributo IDENTITY. La chiave di questa tabella è l’ID, quindi creiamo una PRIMARY KEY
per rendere i record univoci. Infine assegniamo un ordine all’indice, per velocizzare l’esecuzione di query su questa tabella.
Ricordiamo che è possibile imparare T-SQL tramite il Management Studio. Dopo aver creato la tabella nel Management Studio premendo con il tasto
destro del mouse sulla stessa, possiamo selezionare crea script CREATE e si aprirà una finestra contenete lo script di creazione.
Modifica di tabelle esistenti
L’operazione di modifica può essere eseguita sia su tabelle prive di record che su tabelle con dati. Attenzione perché se dovessimo modificare il tipo di dati
di una determinata colonna, SQL non garantisce l’integrità dei dati.
Anche per la modifica delle tabelle possiamo avvalerci di entrambi gli strumenti disponibili in SQL 2005, T-SQL e Management Studio.
Modifica attraverso Management Studio
Per aggiungere, modificare o eliminare le colonne di una tabella, è possibile utilizzare Progettazione tabelle posizionando il mouse sopra la tabella e
scegliendo l’opzione Modifica Tabella. In Progettazione tabelle ogni colonna viene visualizzata come riga di una griglia e le colonne della griglia
rappresentano le proprietà della colonna della tabella. Per definire le colonne di una tabella, modificare le proprietà visualizzate nel riquadro sotto
Progettazione tabelle.
Modifica attraverso T-SQL
L’istruzione per modificare una tabella è ALTER TABLE [nometabella]. Di seguito vanno poi elencati i campi o le prorietà che si vogliono modificare.
ALTER TABLE ANAGRAFICA
ALTER COLUMN ANA_NOME VARCHAR(100)
Listato 2. Istruzione ALTER TABLE
È possibile modificare o eliminare un campo, tramite il comando DROP, oppure un indice o una chiave.
Oppure possiamo attivare o disattivare un trigger tramite il comando ENABLE/DISABLE.
I Vincoli
Un vincolo non è altro che un blocco, una costrizione o a volte può essere inteso anche come un controllo che viene applicato ad una o più
colonne della tabella.
Figura 2. Risultato finale
Per ogni campo creato è possibile inserire molte informazioni. Queste informazioni le troviamo nel pannello sotto la griglia.
Come si può notare le informazioni visualizzate cambiano in base al tipo di dato che stiamo assegnando al campo stesso.
USE [MyDatabase]
GO
CREATE TABLE [dbo].[ANAGRAFICA](
[ANA_ID] [int] IDENTITY(1,1) NOT NULL,
[ANA_NOME] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_COGNOME] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_ANNO_NASCITA] [datetime] NULL,
[ANA_INDIRIZZO] [varchar](150) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_CIVICO] [smallint] NULL,
[ANA_CAP] [int] NULL,
[ANA_PROVINCIA] [varchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_NAZIONE] [varchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_TELEFONO] [varchar](20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_CELLULARE] [varchar](20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ANA_EMAIL] [varchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT [PK_ANAGRAFICA] PRIMARY KEY CLUSTERED
(
[ANA_ID] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
Listato 1. T-SQL per creazione tabella Anagrafica
Il campo ANA_ID è di tipo contatore, quindi utilizziamo l’attributo IDENTITY. La chiave di questa tabella è l’ID, quindi creiamo una PRIMARY KEY
per rendere i record univoci. Infine assegniamo un ordine all’indice, per velocizzare l’esecuzione di query su questa tabella.
Ricordiamo che è possibile imparare T-SQL tramite il Management Studio. Dopo aver creato la tabella nel Management Studio premendo con il tasto
destro del mouse sulla stessa, possiamo selezionare crea script CREATE e si aprirà una finestra contenete lo script di creazione.
Modifica di tabelle esistenti
L’operazione di modifica può essere eseguita sia su tabelle prive di record che su tabelle con dati. Attenzione perché se dovessimo modificare il tipo di dati
di una determinata colonna, SQL non garantisce l’integrità dei dati.
Anche per la modifica delle tabelle possiamo avvalerci di entrambi gli strumenti disponibili in SQL 2005, T-SQL e Management Studio.
Modifica attraverso Management Studio
Per aggiungere, modificare o eliminare le colonne di una tabella, è possibile utilizzare Progettazione tabelle posizionando il mouse sopra la tabella e
scegliendo l’opzione Modifica Tabella. In Progettazione tabelle ogni colonna viene visualizzata come riga di una griglia e le colonne della griglia
rappresentano le proprietà della colonna della tabella. Per definire le colonne di una tabella, modificare le proprietà visualizzate nel riquadro sotto
Progettazione tabelle.
Modifica attraverso T-SQL
L’istruzione per modificare una tabella è ALTER TABLE [nometabella]. Di seguito vanno poi elencati i campi o le prorietà che si vogliono modificare.
ALTER TABLE ANAGRAFICA
ALTER COLUMN ANA_NOME VARCHAR(100)
Listato 2. Istruzione ALTER TABLE
È possibile modificare o eliminare un campo, tramite il comando DROP, oppure un indice o una chiave.
Oppure possiamo attivare o disattivare un trigger tramite il comando ENABLE/DISABLE.
I Vincoli
Un vincolo non è altro che un blocco, una costrizione o a volte può essere inteso anche come un controllo che viene applicato ad una o più
colonne della tabella.
Ritorna all'indice
1.09 - Le viste
Una vista è una tabella virtuale il cui contenuto è definito da una query. In modo analogo a una tabella, una vista è costituita da un set
di colonne e righe di dati denominate.
è possibile considerare una vista come una tabella virtuale o una query archiviata. Se una vista non è indicizzata, i relativi dati non vengono
archiviati nel database sotto forma di oggetto distinto. Nel database viene archiviata solo un’istruzione SELECT.
Il set di risultati dell’istruzione SELECT costituisce la tabella virtuale restituita dalla vista. è possibile utilizzare questa tabella
virtuale facendo riferimento al nome della vista nelle istruzioni Transact-SQL, con la stessa modalità utilizzata per fare riferimento a
una tabella.
Tipologie di viste
In SQL Server 2005 è possibile creare viste standard, viste indicizzate e viste partizionate.
Una vista standard consente di combinare i dati di una o più tabelle e di sfruttare la maggior parte dei vantaggi derivanti dall’utilizzo
delle viste, tra cui la possibilità di concentrare l’attenzione su dati specifici e di semplificare le operazioni di modifica dei dati.
Una vista indicizzata è una vista che è stata materializzata, ovvero calcolata e archiviata. Per indicizzare una vista, è necessario creare
su di essa un indice cluster univoco. Le viste indicizzate consentono di migliorare notevolmente le prestazioni di alcuni tipi di query e
risultano ideali per le query che prevedono l’aggregazione di molte righe. Non sono invece adatte per i set di dati sottostanti che vengono
aggiornati di frequente.
Una vista partizionata unisce dati partizionati in senso orizzontale da un set di tabelle membro appartenenti a uno o più server.
In tal modo i dati risulteranno appartenenti a un’unica tabella. Una vista che unisce tabelle membro nella stessa istanza di SQL Server
costituisce una vista partizionata locale.
Creazione di una vista standard
Per creare una vista in SQL 2005, dobbiamo poter disporre di privilegi idonei e dobbiamo attenerci ad alcune semplici regole.
- Le viste possono essere create solamente nel Database in uso
- Si possono creare viste di viste
- Le viste non possono avere clausole ORDER
- Non si possono creare viste su tabelle temporanee
Creazione tramite Management Studio
Come per la creazione di una tabella, anche per creare una vista basta selezionare la cartella viste all’interno di Management Studio,
premere il tasto destro del mouse e selezionare crea vista.
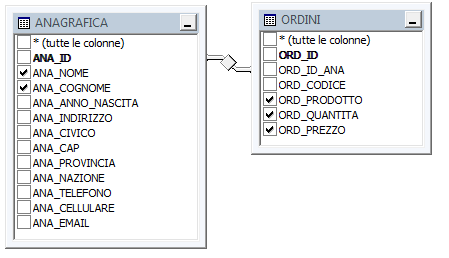 Figura 1. Schema vista ANA_ORDINI
Durante la creazione di una vista in management Studio, possiamo selezionare una o più tabelle o viste, che prenderanno parte alla creazione.
Management Studio propone già la sintassi SQL della query che verrà eseguita ogni volta che si richiamerà la vista.
Questa non è la sintassi T-SQL per la creazione della vista, ma la sua SELECT.
Una volta ottenuto il risultato desiderato, premendo CTRL+S andremo a salvare la vista. A questo punto potremo effettuare le query come
se fosse una semplice tabella.
Creazione tramite T-SQL
CREATE VIEW [dbo].[ANA_ORDINI]
AS
SELECT
dbo.ANAGRAFICA.ANA_NOME,
dbo.ANAGRAFICA.ANA_COGNOME,
dbo.ORDINI.ORD_PRODOTTO,
dbo.ORDINI.ORD_QUANTITA,
dbo.ORDINI.ORD_PREZZO
FROM
dbo.ANAGRAFICA INNER JOIN
dbo.ORDINI ON dbo.ANAGRAFICA.ANA_ID = dbo.ORDINI.ORD_ID_ANA
Listato 1. Creazione vista ANA_ORDINI
Il comando per la creazione di una vista, richiede la presenza di una istruzione SELECT nella quale bisogna specificare i campi che volgiamo
visualizzare. In questo caso abbiamo usato un legame di tipo INNER JOIN per legare l’ID del cliente a quello dell’ordine.
Modificare una vista
La modifica di una vista tramite Management Studio risulta molto semplice. Per prima cosa dobbiamo selezionare la vista e poi procedere con
il comando da menu modifica vista. La schermata che avremo a disposizione sarà la stessa di quella di creazione.
Modifica di una vista tramite T-SQL
Tramite il linguaggio T-SQL, dobbiamo usare l’istruzione ALTER VIEW. Dopo il comando ALTER dovremo inserire le opzioni o i campi da modificare.
Possiamo, ad esempio, modificare completamente l’istruzione di SELECT oppure cambiare semplicemente la clausola WHERE.
ALTER VIEW [dbo].[ANA_ORDINI]
AS
SELECT dbo.ANAGRAFICA.ANA_NOME,
dbo.ANAGRAFICA.ANA_COGNOME,
dbo.ORDINI.ORD_PRODOTTO,
dbo.ORDINI.ORD_QUANTITA,
dbo.ORDINI.ORD_PREZZO
FROM dbo.ANAGRAFICA INNER JOIN dbo.ORDINI
ON dbo.ANAGRAFICA.ANA_ID = dbo.ORDINI.ORD_ID_ANA
WHERE dbo.ORDINI.ORD_PREZZO > 100.00
GO
Listato 2. Modifica vista ANA_ORDINI
Figura 1. Schema vista ANA_ORDINI
Durante la creazione di una vista in management Studio, possiamo selezionare una o più tabelle o viste, che prenderanno parte alla creazione.
Management Studio propone già la sintassi SQL della query che verrà eseguita ogni volta che si richiamerà la vista.
Questa non è la sintassi T-SQL per la creazione della vista, ma la sua SELECT.
Una volta ottenuto il risultato desiderato, premendo CTRL+S andremo a salvare la vista. A questo punto potremo effettuare le query come
se fosse una semplice tabella.
Creazione tramite T-SQL
CREATE VIEW [dbo].[ANA_ORDINI]
AS
SELECT
dbo.ANAGRAFICA.ANA_NOME,
dbo.ANAGRAFICA.ANA_COGNOME,
dbo.ORDINI.ORD_PRODOTTO,
dbo.ORDINI.ORD_QUANTITA,
dbo.ORDINI.ORD_PREZZO
FROM
dbo.ANAGRAFICA INNER JOIN
dbo.ORDINI ON dbo.ANAGRAFICA.ANA_ID = dbo.ORDINI.ORD_ID_ANA
Listato 1. Creazione vista ANA_ORDINI
Il comando per la creazione di una vista, richiede la presenza di una istruzione SELECT nella quale bisogna specificare i campi che volgiamo
visualizzare. In questo caso abbiamo usato un legame di tipo INNER JOIN per legare l’ID del cliente a quello dell’ordine.
Modificare una vista
La modifica di una vista tramite Management Studio risulta molto semplice. Per prima cosa dobbiamo selezionare la vista e poi procedere con
il comando da menu modifica vista. La schermata che avremo a disposizione sarà la stessa di quella di creazione.
Modifica di una vista tramite T-SQL
Tramite il linguaggio T-SQL, dobbiamo usare l’istruzione ALTER VIEW. Dopo il comando ALTER dovremo inserire le opzioni o i campi da modificare.
Possiamo, ad esempio, modificare completamente l’istruzione di SELECT oppure cambiare semplicemente la clausola WHERE.
ALTER VIEW [dbo].[ANA_ORDINI]
AS
SELECT dbo.ANAGRAFICA.ANA_NOME,
dbo.ANAGRAFICA.ANA_COGNOME,
dbo.ORDINI.ORD_PRODOTTO,
dbo.ORDINI.ORD_QUANTITA,
dbo.ORDINI.ORD_PREZZO
FROM dbo.ANAGRAFICA INNER JOIN dbo.ORDINI
ON dbo.ANAGRAFICA.ANA_ID = dbo.ORDINI.ORD_ID_ANA
WHERE dbo.ORDINI.ORD_PREZZO > 100.00
GO
Listato 2. Modifica vista ANA_ORDINI
Ritorna all'indice
1.10 - Le store procedure
Per sfruttare le potenzialità di SQL Server, viene messo a disposizione un linguaggio di programmazione chiamato T-SQL.
Durante lo sviluppo di una applicazione Client le richieste per l’interrogazione di dati possono essere inviate direttamente al database, dal
programma, tramite istruzioni di INSERT, SELECT, UPDATE o altro ancora, oppure è possibile creare piccoli programmi o funzioni all’interno del
Si tratta di moduli o routine che incapsulano codice in modo da poterlo riutilizzare. Una stored procedure può accettare parametri di input,
restituire al client risultati tabulari o scalari, richiamare istruzioni DDL (Data Definition Language) e DML (Data Manipulation Language) e
restituire parametri di output. Le stored procedure di SQL Server 2005 possono essere di due tipi: Transact-SQL o CLR.
Come per un programma, anche una Stored Procedure è in grado di accettare o ricevere parametri, restituire valori anche calcolati, effettuare
scelte. Questo oggetto è utilissimo per diversi motivi tra cui la sicurezza e le performance. Per questi motivi, specialmente nello sviluppo
di applicazioni client/server, le Stored Procedure dovrebbero essere preferite alle semplici istruzioni SQL.
Tipologie di Stored Procedure
All’interno di SQL 2005 possiamo creare diverse tipologie di Stored Procedure, una prima suddivisione va fatta tra: stored utente, stored estese
e stored di sistema.
Stored definite dall’utente
Si dividono in Transact-SQL e CLR. Una stored procedure Transact-SQL è un insieme salvato di istruzioni Transact-SQL che può accettare e restituire
parametri specificati dall’utente. Ad esempio, una stored procedure può contenere le istruzioni necessarie per inserire una nuova riga in una
o più tabelle in base alle informazioni fornite dall’applicazione client oppure può restituire dati del database all’applicazione client.
Ad esempio, un’applicazione Web per l’e-commerce può utilizzare una stored procedure per restituire informazioni su prodotti specifici in base
ai criteri di ricerca specificati dall’utente in linea.
Una stored procedure CLR è un riferimento a un metodo Common Language Runtime (CLR) di Microsoft .NET Framework che può accettare e restituire
parametri specificati dall’utente. Viene implementata come un metodo pubblico statico su una classe in un assembly .NET Framework.
Stored Procedure di Sistema
Molte attività amministrative di SQL Server 2005 vengono eseguite tramite un tipo speciale di procedura nota come stored procedure di sistema.
Le stored procedure di sistema sono archiviate nel database Resource, includono il prefisso sp_ e vengono visualizzate nello schema sys di
tutti i database di sistema e definiti dall’utente. In SQL Server 2005, è possibile applicare alle stored procedure di sistema le autorizzazioni
GRANT, DENY e REVOKE.
Ritorna all'indice
1.11 - Creazione di una Stored Procedure
Per creare una Stored Procedure dobbiamo avviare il Management Studio, aprire la cartella Stored Procedure del nostro database e scelgiere la
solita opzione Crea stored. A questo punto ci viene messo a disposizione un editor con alcune istruzioni già pronte:
— =============================================
— Author:
— Create date:
— Description:
— =============================================
CREATE PROCEDURE
<@Param1, sysname, @p1> = ,
<@Param2, sysname, @p2> =
AS
BEGIN
SELECT <@Param1, sysname, @p1>, <@Param2, sysname, @p2>
RETURN <@Param1, sysname, @p1>
END
GO
Listato 1. Testo per creare una stored procedure
Come si nota la Stored procedure comprende una prima sezione per la dichiarazione di parametri che possono essere di input oppure di output.
Una seconda sezione che esegue una o più istruzione SQL ed infine la restituzione del parametro stesso.
Utilizzo dei parametri
La caratteristica più importante delle stored è che sono delle procedure in grado di ricevere e restituire parametri.
In questo modo abbiamo la possibilità di riciclare il nostro codice e parametrizzarlo.
Per esempio, se volessimo creare una Stored che ci faccia visualizzare solamente gli orgini con una cifra superiore ad un parametro che
vogliamo noi:
USE MyDatabase
GO
CREATE PROCEDURE ORDINI_PAR
— parametro prezzo di tipo money
@PREZZO money = 0
AS
BEGIN
SET NOCOUNT ON;
SELECT * FROM ANA_ORDINI
WHERE ORD_PREZZO >= @PREZZO
END
GO
Listato 2. Stored Procedure ORDINI_PAR
Se volessimo richiamare questa stored, potremmo farlo, ad esempio, per sapere quanti ordini hanno i prodotti che superano i 100 €.
Aprendo un semplice editor di query bisogna dichiarare il parametro ed eseguire la stored.
USE [MyDatabase]
GO
EXEC [dbo].[ORDINI_PAR]
@PREZZO = 0
GO
Listato 3. Esecuzione Stored ORDINI_PAR
Stored Procedure per modificare i dati
Le Stored Procedure, oltre ad essere utilizzate per restituire delle informazioni dal database, possono essere utilizzate anche per modificare
o aggiungere dati al database. Possiamo, per esempio, usare una Stored Procedure per inserire un nuovo record e di questo, prelevare l’ID per
renderlo visibile all’applicazione.
Nell’esempio che segue dobbiamo creare una Stored in grado di inserire un nuovo ordine nel database e informarci sull’ID creato.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE INSERISCI_ORDINE
@ORDINE_ID INT OUTPUT,
@ID_UTENTE INT,
@CODICE VARCHAR(50),
@PRODOTTO VARCHAR(100),
@QUANTITA INT,
@PREZZO MONEY
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO ORDINI
(ORDINI.ORD_ID_ANA,
ORDINI.ORD_CODICE,
ORDINI.ORD_PRODOTTO,
ORDINI.ORD_QUANTITA,
ORDINI.ORD_PREZZO)
VALUES (@ID_UTENTE,
@CODICE, @PRODOTTO, @QUANTITA, @PREZZO);
SET @ORDINE_ID = (SELECT @@IDENTITY);
END
GO
Listato 4. Stored INSERISCI_ORDINE
Ritorna all'indice
1.12 - I vincoli
I vincoli sono dei controlli che vengono implementati in una o più colonne di una tabella. Esistono diverse tipologie di vincolo: vincoli di
chiave, per il controllo di unicità o per il semplice controllo di null.
Vincoli di chiave primaria
Il vincolo di chiave primaria è il più importante poiché è l’unico in grado di contrassegnare l’unicità del recordset, per la tabella.
Un vincolo di c.p. può essere costituito da una o più colonne, ma ne può esistere solo uno per ogni tabella.
Una chiave primaria deve essere breve e semplice.
Breve perché non deve occupare troppo spazio e non deve essere difficile da implementare.
Semplice perché deve essere facile da memorizzare e da visualizzare.
Pensate ad un semplice campo int che si incrementa di 1 ad ogni record e ad un varchar(20) per codice bancario random… naturalmente l’int è
più efficace.
ALTER TABLE [dbo].[ANAGRAFICA]
ADD CONSTRAINT [PK__ANAGRAFICA] PRIMARY KEY CLUSTERED(
ANA_ID ASC,
ANA_NOME ASC,
ANA_COGNOME ASC
)
Listato 1. Creazione di un vincolo di chiave primaria composto da 3 colonne
Con questo codice abbiamo detto a SQL Server di creare un indice di chiave primaria e di legarlo con i 3 campi: ID, nome e cognome.
In questo caso basterebbe vincolare il campo ID e renderlo IDENTITY, ovvero in grado di incrementarsi da solo.
Occuperemmo meno memoria e il motore di database renderebbe di più.
Ritorna all'indice
1.13 -
Ritorna all'indice
1.14 -
Ritorna all'indice
1.15 -
Ritorna all'indice
1.16 -
Ritorna all'indice
1.17 -
Ritorna all'indice
1.18 -
Ritorna all'indice
1.19 -
|